Optimizing server-side storefront rendering at Shopify
This post originally appeared on the Shopify Engineering blog on December 10, 2020. I co-wrote it with my colleague Celso Dantas, Staff Developer at Shopify.
In the previous post about Shopify's new storefront rendering engine, we described how we went about the rewrite process and smoothly transitioned to serve storefront requests with the new implementation. As a follow-up and based on readers’ comments and questions, this post dives deeper into the technical details of how we built the new storefront rendering engine to be faster than the previous implementation.
To set the table, let’s see how the new storefront rendering engine performs:
- It generates a response in less than ~45ms for 75% of storefront requests;
- It generates a response in less than ~230ms for 90% of storefront requests;
- It generates a response in less than ~900ms for 99% of storefront requests.
Thanks to the new storefront rendering engine, the average storefront response is nearly 5x faster than with the previous implementation. Of course, how fast the rendering engine is able to process a request and spit out a response depends on two key factors: the shop’s Liquid theme implementation, and the number of resources needed to process the request. To get a better idea of where the storefront rendering engine spends its time when processing a request, try using the Shopify Theme Inspector: this tool will help you identify potential bottlenecks so you can work on improving performance in those areas.
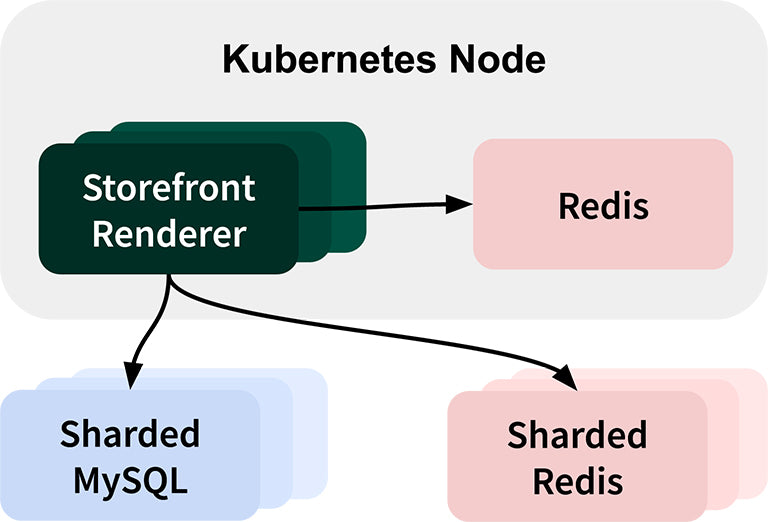
Before we cover each topic, let’s briefly describe our application stack. As mentioned in the previous post, the new storefront rendering engine is a Ruby application. It talks to a sharded MySQL database and uses Redis to store and retrieve cached data.
Optimizing how we load all that data is extremely important. As one of our requirements was to improve rendering time for Storefront requests. Here are some of the approaches that we took to accomplish that.
Using MySQL’s multi-statement feature to reduce round trips
To reduce the number of network round trips to the database, we use MySQL’s multi-statement feature to allow sending multiple queries at once. With a single request to the database, we can load data from multiple tables at once. Here’s a simplified example:
This request is especially useful to batch-load a lot of data very early in the response lifecycle based on the incoming request. After identifying the type of request, we trigger a single multi-statement query to fetch the data we need for that particular request in one go, which we’ll discuss later in this blog post. For example, for a request for a product page, we’ll load data for the product, its variants, its images, and other product-related resources in addition to information about the shop and the storefront theme, all in a single round-trip to MySQL.
Implementing a thin data mapping layer
As shown above, the new storefront rendering engine uses handcrafted, optimized SQL queries. This allows us to easily write fine-tuned SQL queries to select only the columns we need for each resource and leverage JOINs and sub-SELECT statements to optimize data loading based on the resources to load which are sometimes less straightforward to implement with a full-service object-relational mapping (ORM) layer.
However, the main benefit of this approach is the tiny memory footprint of using a raw MySQL client compared to using an object-relational mapping (ORM) layer that’s unnecessarily complex for our needs. Since there’s no unnecessary abstraction, forgoing the use of an ORM drastically simplifies the flow of data. Once the raw rows come back from MySQL, we effectively use the simplest ORM possible: we create plain old Ruby objects from the raw rows to model the business domain. We then use these Ruby objects for the remainder of the request. Below is an example of how it’s done.
Of course, not using an ORM layer comes with a cost: if implemented poorly, this approach can lead to more complexity leaking into the application code. Creating thin model abstractions using plain old Ruby objects prevents this from happening, and makes it easier to interact with resources while meeting our performance criteria. Of course, this approach isn’t particularly common and has the potential to cause panic in software engineers who aren’t heavily involved in performance work, instead worrying about schema migrations and compatibility issues. However, when speed is critical, we accept to take on that complexity.
Book-keeping and eager-loading queries
An HTTP request for a Shopify storefront may end up requiring many different resources from data stores to render properly. For example, a request for a product page could lead to requiring information about other products, images, variants, inventory information, and a whole lot of other data not loaded on multi-statement select. The first time the storefront rendering engine loads this page, it needs to query the database, sometimes making multiple requests, to retrieve all the information it needs. This usually happens during the request at any given time.
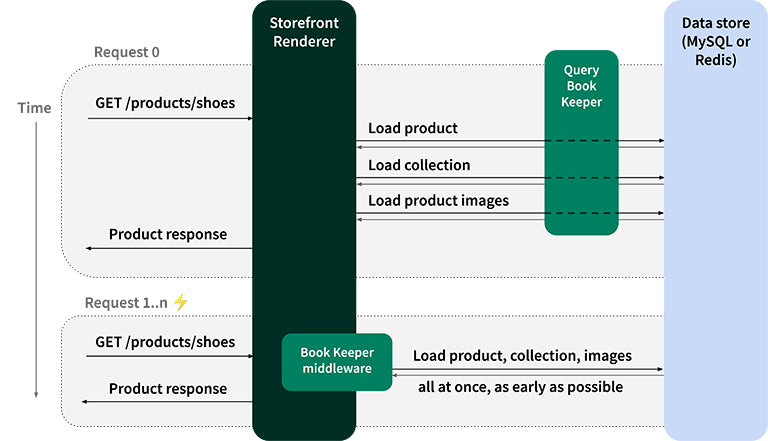
As it retrieves this data for the first time, the storefront rendering engine keeps track of the queries it performed on the database for that particular product page and stores that list of queries in a key-value store for later use. When an HTTP request for the same product page comes in later (which it knows when the cache key matches), the rendering engine looks up the list of queries it performed throughout the previous request of the same type and performs those queries all at once, at the very beginning of the current request, because we’re pretty confident we’ll need them for this request (since they were used in the previous request).
This book-keeping mechanism lets us eager-load data we’re pretty confident we’ll need. Of course, when a page changes, this may lead to over-fetching and/or under-fetching, which is expected, and the shape of the data we fetch stabilizes quickly over time as more requests come in.
On the other side, some liquid models of Shopify’s storefronts are not accessed as frequently, and we don’t need to eager-load data related to them. If we did, we’d increase I/O wait time for something that we probably wouldn’t use very often. What the new rendering engine does instead is lazy-load this data by default. Unless the book-keeping mechanism described above eager-loads it, we’ll defer retrieving data to only load it if it’s needed for a particular request.
Implementing caching layers
Much like a CPU’s caching architecture, the new rendering engine implements multiple layers of caching to accelerate responses.
A critical aside before we jump into this section: adding caching should never be the first step towards building performance-oriented software. Start by building a solution that’s extremely fast from the get go, even without caching. Once this is achieved, then consider adding caching to reduce load on the various components on the system while accelerating frequent use cases. Caching is like a sharp knife and can introduce hard to detect bugs.
In-memory cache

At the frontline of our caching system is an in-memory cache that you can essentially think of as a global hash that’s shared across requests within each web worker. Much like the majority of our caching mechanisms, this caching layer uses the LRU caching algorithm. As a result, we use this caching layer for data that’s accessed very often. This layer is especially useful in high throughput scenarios such as flash sales.
Node-local shared caching
As a second layer on top of the in-memory cache, the new rendering engine leverages a node-local Redis store that’s shared across all server workers on the same node. Since the database is available on the same machine as the rendering engine process itself, this node-local data transfer prevents network overhead and improves response times. As a result, multiple Ruby processes benefit from sharing cached data with one another.
Full-page caching
Once the rendering engine successfully renders a full storefront response for a particular type of request, we store the final output (most often an HTML or JSON string) into the local Redis for later retrieval for subsequent requests that match the same cache key. This full-page caching solution lets us prevent regenerating storefront responses if we can by using the output we previously computed.
Database query results caching
In a scenario where the full-page output cache, the in-memory cache, and the node-local cache doesn’t have a valid entry for a given request, we need to reach all the way to the database. Once we get a result back from MySQL, we transparently cache the results in Redis for later retrieval based on the queries and their parameters. As long as the cache keys don’t change, running the same database queries over and over always hit Redis instead of reaching all the way to the database.
Liquid object memoizer
Thanks to the Liquid templating language, merchants and partners may build custom storefront themes. When loading a particular storefront page, it’s possible that the Liquid template to render includes multiple references to the same object. This is common on the product page for example, where the template will include many references to the product object: {{ product.title }}, {{ product.description }}, {{ product.featured_media }}, and others.
Of course, when each of these are executed, we don’t fetch the product over and over again from the database—we fetch it once, then keep it in memory for later use throughout the request lifecycle. This means that if the same product object is required multiple times at different locations during the render process, we’ll always use the same one and only instance of it throughout the entire request lifecycle.
The Liquid object memoizer is especially useful when multiple different Liquid objects end up loading the same resource. For example, when loading multiple product objects on a collection page using and then referring to a particular product using {{ all_products['cowboy-hat'] }} on a collection page, with the Liquid object memoizer we’ll load it from an external data store once, then store it in memory and fetch it from there if it’s needed later. On average, across all Shopify storefronts, we see that the Liquid object memoizer prevents between 16 and 20 accesses to Redis and/or MySQL for every single storefront request, where we leverage the in-memory cache instead. In some extreme cases, we see that the memoizer prevents up to 4,000 calls to data stores per request.
Reducing memory allocations
Writing memory-aware code
Garbage collection execution is expensive. So we write code that doesn’t generate unnecessary objects. Use of methods and algorithms that modify objects in place, instead of generating a new object. For example:
- use
#map!instead of#mapwhen dealing with lists. It prevents a new Array object from being created. - Use string interpolation instead of string concatenation. Interpolation does not create intermediate unnecessary String objects.
This may not seem like much, but consider this: using #map! instead of #map could reduce your memory usage significantly, even when simply looping over an array of integers to double the values.
Let’s set up an following array of 1000 integers from 1 to 1000:
array = (1..1000).to_a
Then, let’s double each number in the array with Array#map:
array.map { |i| i * 2 }
The line above leads to one object allocated in memory, for a total of 8040 bytes.
Now let’s do the same thing with Array#map! instead:
array.map! { |i| i * 2 }
The line above leads to zero object allocated in memory, for a total of 0 bytes.
Even with this tiny example, using map! instead of map saves ~8 kilobytes of allocated memory, and considering the sheer scale of the Shopify platform and the storefront traffic throughput it receives, every little bit of memory optimization counts to help the garbage collector run less often and for smaller periods of time, thus improving server response times.
With that in mind, we use tracing and profiling tools extensively to dive deeper into areas in the rendering engine that are consuming too much memory and to make precise changes to reduce memory usage.
Post-publication addendum: the Rubocop team offers a set of performance-oriented cops that highlight potential performance improvements - I highly recommend trying them out!
Method-specific memory benchmarking
To prevent accidentally increasing memory allocations, we built a test helper method that lets us benchmark a method or a block to know many memory allocations and allocated bytes it triggers. Here’s how we use it:
This benchmark test will succeed if calling Product.find_by_handle('cowboy-hat') matches the following criteria:
- The call allocates between 48 and 52 objects in memory;
- The call allocates between 5100 and 5200 bytes in memory.
We allow a range of allocations because they’re not deterministic on every test run. This depends on the order in which tests run and the way data is cached, which can affect the final number of allocations.
As such, these memory benchmarks help us keep an eye on memory usage for specific methods. In practice, they’ve prevented introducing inefficient third-party gems that bloat memory usage, and they’ve increased awareness of memory usage to developers when working on features.
We covered three main ways to improve server-side performance: batching up calls to external data stores to reduce roundtrips, caching data in multiple layers for specific use cases, and simplifying the amount of work required to fulfill a task by reducing memory allocations. When they’re all combined, these approaches lead to big time performance gains for merchants on the platform—the average response time with the new rendering engine is 5x faster than with the previous implementation.
Those are just some of the techniques that we are using to make the new application faster. And we never stop exploring new ways to speed up merchant’s storefronts. Faster rendering times are in the DNA of our team!
This blog post is not available under a Creative Commons license.